Appendix: Atomic Compare-and-set Operations
Note on appendices: these chapters are included as appendices because these techniques, for all their benefits, don’t yet have support from Ruby core.
I didn’t mention it previously, but there are really two camps in the multi-threaded world. It’s not as though these two camps oppose each other, but there are very different ways to structure concurrent programs.
The ‘old guard’ tends to lean on the synchronization mechanisms that you’ve already seen. That means lots of mutexes and condition variables. These methods are tried and true, but there are obvious drawbacks. Things like deadlocks and mutex bottlenecks are just two examples.
The newer camp is emerging from academia, offering a different approach to writing concurrent programs. Although many of these concepts are still theoretical in nature, many of them are seeing more widespread use and experimentation. These are things like lockless, lock-free, and wait-free data structures, immutable data structures, software transactional memory, and things of this nature.
Covering all of these emerging topics would require a book in and of itself, and many of them are still stabilizing as they see real-world usage. In this chapter I’ll look at atomic compare-and-set (CAS) operations, which is really the building block underlying these newer approaches. In the next chapter I’ll give more coverage to immutability and how it relates to thread safety.
Overview
Here’s a brief outline of how the CAS operation works.
In Ruby, you first create an Atomic instance that holds a value.
item = Atomic.new('value')
This comes from the ‘atomic’ rubygem. This gem provides a consistent Ruby API for CAS operations across MRI, JRuby, and Rubinius. It’s great!
The Atomic API does provide a higher-level, Ruby-ish API, but the lower-level workhorse method is Atomic#compare_and_set(old, new). You pass it the value that you think it currently holds and the value you want to set it to.
If the current value is the one you expected it to be, it’s updated to your new value. Otherwise, it returns false. At this point you have to decide whether to retry the operation or just continue on.
This compare-and-set operation is hardware-supported and provides a guarantee you wouldn’t have otherwise. In the next section, I’ll illustrate this with code. In a situation where you want to read a value, modify it, and then update it, it’s possible to read a value, then have another thread update the value before you can, leading to a situation where your update can overwrite the work done by another thread.
Code-driven example
A few chapters back, you had a quick look at the += operator. Although this is an operator in Ruby, it offers no thread-safety guarantees since it will be expanded to at least 3 operations under the hood. Let’s review that.
When you use the += operator like this: @counter += 1, Ruby must do at least the following:
- Get the current value of
@counter. - Increment the retrieved value by 1.
- Assign the new value back to
@counter.
It looks roughly like this in code:
@counter = 0
# Get the current value of `@counter`.
current_value = @counter
# Increment the retrieved value by 1.
new_value = current_value + 1
# Assign the new value back to `@counter`.
@counter = new_value
You probably wouldn’t write this code, but this illustrates the underlying steps involved.
The problem with this multi-step operation is that it’s not atomic. It’s possible that two threads race past step 1 before either gets to step 3. In that case, both threads would think the current_value is 0 and assign the value of 1 to @counter in step 3. A correct implementation should end up with @counter equal to 2 with two threads.
The old guard would solve this problem with a mutex:
@counter = 0
@mutex = Mutex.new
@mutex.synchronize do
current_value = @counter
new_value = current_value + 1
@counter = new_value
end
This implementation would ensure only one thread can perform this multi-step operation at a time, preserving correctness by limiting the ability of things to happen in parallel. It’s safe to use with multiple threads.
This problem can be solved a different way using CAS. It would look something like this:
require 'atomic'
@counter = Atomic.new(0)
loop do
current_value = @counter.value
new_value = current_value + 1
if @counter.compare_and_set(current_value, new_value)
break
end
end
This version is a bit more code and uses more control structures. However, it doesn’t use any locks and is still safe to use with multiple threads. I’ll walk you through the logic here, then show you a shorthand to make things much more readable. Since this is Ruby, the Atomic class does provide a much more elegant API; however, the set of primitive operations you’re seeing here should be possible in any environment that supports CAS.
require 'atomic'
@counter = Atomic.new(0)
Here, you wrap the value that you want to perform CAS operations on inside of an Atomic object. In this case, our counter value, starting at 0, is wrapped by an Atomic.
loop do
current_value = @counter.value
new_value = current_value + 1
Here’s the main part of the logic. First you enter a loop. The reason for this is so that the whole operation is retried if the compare_and_set fails. I’ll repeat that again: the whole operation is retried if the compare_and_set fails. That means that your operation must be idempotent. In other words, it can be run multiple times without having any additional effects outside of its scope. If something is idempotent, there’s no harm in doing it multiple times, which is exactly what could happen in this case!
Next you grab the current value by using Atomic#value, then calculate the new value by adding 1 to it.
if @counter.compare_and_set(current_value, new_value)
break
end
end
Now for the punch line. You call the compare_and_set method; the first argument is what you expect the value to be; the second argument is the new value that you want to set it to. If the underlying value has not changed, the update will succeed, returning true. In this case nothing needs to be retried so you break out of the loop.
Now for the failure case. Between reading the value into current_value and setting the new value here, it’s possible that another thread has updated this variable. In that case, the operation would fail. The first argument would not be equal to the real current value. In that case, this method returns false and the loop is restarted.
Notice that there’s no locking involved. With the happy path, when the update succeeds, there’s no locking that needs to be done. If the update fails, there’s a different cost to be paid: the whole operation needs to be retried.
What’s the point of this? The point is that for some kinds of operations, locking is very expensive. Since only one thread can be in a critical section at any given time, all other threads need to be put to sleep to wait their turn when they try to execute the same code path. Using a CAS operation, all of the threads remain active. If the cost of retrying the operation is cheap, or rare, it may be much less expensive than using a lock. All this is to say that sometimes a lockless algorithm is much faster than a locking variant, but other times this isn’t the case.
Let’s compare the running times of the locking and lock-free implementations of the += operation. But first, I want to show you the Ruby sugar that Atomic provides.
Since this construct of using a loop to retry operations is so common, Atomic supports an update method that encapsulates this. We can re-write our previous CAS example like so:
require 'atomic'
@counter = Atomic.new(0)
@counter.update { |current_value|
current_value + 1
}
You pass a block to the update method. Under the covers it will fetch the current value, then call this block, passing the current value as a block variable. The result of evaluating the block is taken to be the new value you want to set, which is then used for the compare_and_set operation. If the operation fails, the block is called again, passing in the updated current value. As I mentioned, it’s important that this block is idempotent, as it may be called multiple times.
I think we can all agree that this version is more elegant, with more of a Ruby-ish feel to the API. On to the benchmark.
Benchmark
I simply took the locking and lockless variants of the counters presented in this chapter and benchmarked them against each other. In this simple benchmark, I had 100 threads each incrementing the counter 10,000 times. To be sure, this is an abnormally high workload for a counter, normally the threads would also be engaged in other behaviour. Nonetheless, here is a plot of the results from running code/benhcmarks/locking_vs_lockless.rb.
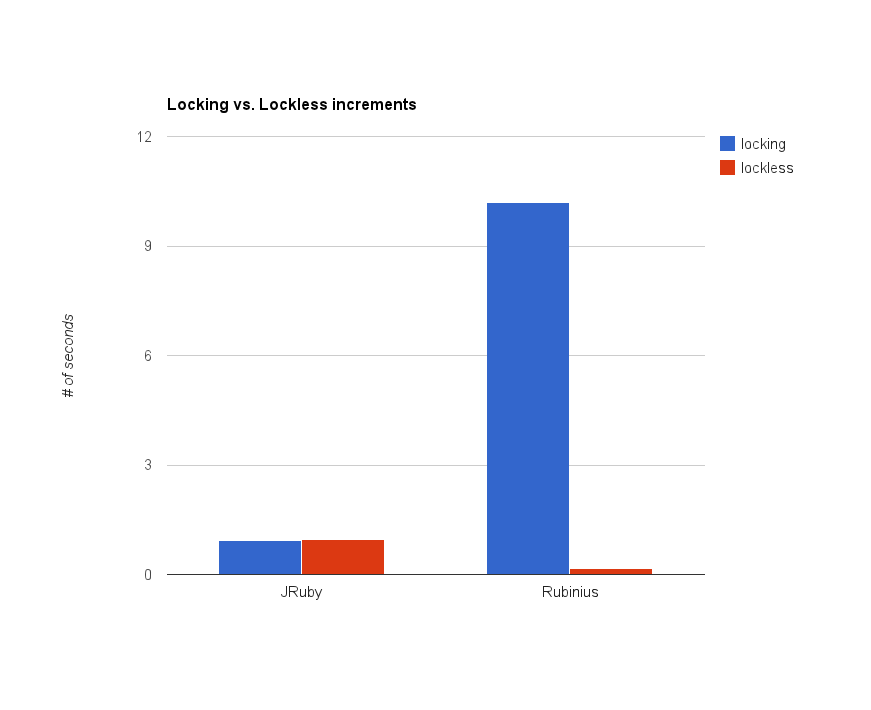
As expected, the results differ wildly between implementations. With JRuby, the locking variant was consistently on par with the lockess variant. With Rubinius, however, the lockless variant was consistently faster by about 10x. Don’t expect these results to hold in all situations. As always, the only surefire way to know what will work for your code is to measure.
CAS as a primitive
We’ve been looking at CAS operations as an alternative to locking solutions. They certainly can be used this way, but research has shown that CAS are perhaps more useful as a lower-level abstraction. Indeed, it’s been proven that with this one primitive, you can implement any lock-free algorithm.
Some new technologies, such as Clojure, take full advantage of this and are showing what’s really possible with multi-threaded concurrency. In the end, CAS operations don’t provide a silver bullet. In some situations it can provide speed increases, in other situations, new functionality.
As far as Ruby goes, there’s not much support for these kinds of approaches. There’s the ‘atomic’ rubygem, and a few experimental data structures floating around (One can be found at https://gist.github.com/jstorimer/5298581, the other is an implementation of the Disruptor algorithm at https://github.com/ileitch/disruptor). However, now that we have a CAS primitive available in Ruby, many academic papers outlining algorithms should be applicable.