Protecting Data with Mutexes
Mutexes provide a mechanism for multiple threads to synchronize access to a critical portion of code. In other words, they help bring some order, and some guarantees, to the world of multi-threaded chaos.
Mutual exclusion
The name ‘mutex’ is shorthand for ‘mutual exclusion.’ If you wrap some section of your code with a mutex, you guarantee that no two threads can enter that section at the same time.
I’ll demonstrate first using the silly Array-pushing example from the previous chapter.
shared_array = Array.new
mutex = Mutex.new
10.times.map do
Thread.new do
1000.times do
mutex.lock
shared_array << nil
mutex.unlock
end
end
end.each(&:join)
puts shared_array.size
This slight modification is guaranteed to produce the correct result, across Ruby implementations, every time. The only difference is the addition of the mutex.
$ ruby code/snippets/concurrent_array_pushing_with_mutex.rb
10000
$ jruby code/snippets/concurrent_array_pushing_with_mutex.rb
10000
$ rbx code/snippets/concurrent_array_pushing_with_mutex.rb
10000
Let’s step through the changes.
Besides creating the mutex with Mutex.new, the important bits are the lines above and below the <<. Here they are again:
mutex.lock
shared_array << nil
mutex.unlock
The mutex sets up some boundaries for the thread. The first thread that hits this bit of code will lock the mutex. It then becomes the owner of that mutex.
Until the owning thread unlocks the mutex, no other thread can lock it, thus no other threads can enter that portion of code. This is where the guarantee comes from. The guarantee comes from the operating system itself, which backs the Mutex implementation (See pthread_mutex_init(3)).
In this program, since any thread has to lock the mutex before it can push to the Array, there’s a guarantee that no two threads will be performing this operation at the same time. In other words, this operation can no longer be interrupted before it’s completed. Once one thread begins pushing to the Array, no other threads will be able to enter that portion of code until the first thread is finished. This operation is now thread-safe.
Before I say anything else, I’ll show a more commonly used convenience method that Ruby’s Mutex offers:
mutex.synchronize do
shared_array << nil
end
You pass a block to Mutex#synchronize. It will lock the mutex, call the block, and then unlock the mutex.
The contract
Notice that the mutex is shared among all the threads. The guarantee only works if the threads are sharing the same Mutex instance. In this way, when one thread locks a mutex, others have to wait for it to be unlocked.
I also want to point out that we didn’t modify the << method or the shared_array variable in any way in order to make this thread-safe.
So, if some other part of your code decides to do shared_array << item, but without wrapping it in the mutex, that may introduce a thread-safety issue. In other words, this contract is opt-in. There’s nothing that stops some other part of the code from updating a value without the Mutex.
The block of code inside of a Mutex#synchronize call is often called a critical section, pointing to the fact that this code accesses a shared resource and must be handled correctly.
Making key operations atomic
In the last chapter we looked at multi-step operations, specifically a check-then-set race condition. You can use a mutex to make this kind of operation thread-safe, and we’ll look at the effect of both updating values and reading values with a mutex.
We’ll be reusing the ecommerce order example from the last chapter. Let’s make sure that our customers are only charged once.
# This class represents an ecommerce order
class Order
attr_accessor :amount, :status
def initialize(amount, status)
@amount, @status = amount, status
@mutex = Mutex.new
end
def pending?
status == 'pending'
end
# Ensure that only one thread can collect payment at a time
def collect_payment
@mutex.synchronize do
puts "Collecting payment..."
self.status = 'paid'
end
end
end
# Create a pending order for $100
order = Order.new(100.00, 'pending')
# Ask 5 threads to check the status, and collect
# payment if it's 'pending'
5.times.map do
Thread.new do
if order.pending?
order.collect_payment
end
end
end.each(&:join)
The change here is in the Order#collect_payment method. Each Order now has its own Mutex, initialized when the object is created. The Mutex creates a critical section around the collection of the payment. This guarantees that only one thread can collect payment at a time. Let’s run this against our supported Rubies:
$ ruby code/snippets/concurrent_payment_with_mutex.rb
Collecting payment...
Collecting payment...
Collecting payment...
$ jruby code/snippets/concurrent_payment_with_mutex.rb
Collecting payment...
Collecting payment...
Collecting payment...
Collecting payment...
Collecting payment...
$ rbx code/snippets/concurrent_payment_with_mutex.rb
Collecting payment...
Collecting payment...
Collecting payment...
Huh? This didn’t help at all. We’re still seeing the incorrect result.
The reason is that we put the critical section in the wrong place. By the time the payment is being collected, multiple threads could already be past the ‘check’ phase of the ‘check-and-set’ race condition. In this way, you could have multiple threads queued up to collect payment, but they would do it one at a time.
We need to move the mutex up to a higher level so that both the ‘check’ AND the ‘set,’ in this case checking if the order is pending and collecting the payment, are inside the mutex.
Here’s another go with the mutex in a different spot.
# This class represents an ecommerce order
class Order
attr_accessor :amount, :status
def initialize(amount, status)
@amount, @status = amount, status
end
def pending?
status == 'pending'
end
def collect_payment
puts "Collecting payment..."
self.status = 'paid'
end
end
# Create a pending order for $100
order = Order.new(100.00, 'pending')
mutex = Mutex.new
# Ask 5 threads to check the status, and collect
# payment if it's 'pending'
5.times.map do
Thread.new do
mutex.synchronize do
if order.pending?
order.collect_payment
end
end
end
end.each(&:join)
The change here is that the mutex is now used down inside the block passed to Thread.new. It’s no longer present inside the Order object. The mutex is now a contract between the threads, rather than a contract enforced by the object.
But notice that the mutex now wraps the ‘check’ AND the collect_payment method call. This means that once one thread has entered that critical section, the others must wait for it to finish. So now you have a guarantee that only one thread will check that condition, find it to be true, and collect the payment. You have made this multi-step operation atomic.
Here are the results to prove it:
$ ruby code/snippets/concurrent_payment_with_looser_mutex.rb
Collecting payment...
$ jruby code/snippets/concurrent_payment_with_looser_mutex.rb
Collecting payment...
$ rbx code/snippets/concurrent_payment_with_looser_mutex.rb
Collecting payment...
Now the result is correct every time.
Mutexes and memory visibility
Now I want to throw another question at you. Should the same shared mutex be used when a thread tries to read the order status? In that case, another thread might end up using something like this:
status = mutex.synchronize { order.status }
if status == 'paid'
# send shipping notification
end
If you’re setting a variable while holding a mutex, and other threads want to see the most current value of that variable, they should also perform the read while holding that mutex.
The reason for this is due to low-level details. The kernel can cache in, for instance, L2 cache before it’s visible in main memory. It’s possible that after the status has been set to ‘paid,’ by one thread, another thread could still see the Order#status as ‘pending’ by reading the value from main memory before the change has propagated there.
This generally isn’t a problem in a single-threaded program because race conditions like this don’t happen with one thread. In a multi-threaded program there’s no such guarantee. When one thread writes to memory, that operation may exist in cache before it’s written to main memory. If another thread accesses that memory, it will get a stale value.
The solution to this is something called a memory barrier. Mutexes are implemented with memory barriers, such that when a mutex is locked, a memory barrier provides the proper memory visibility semantics.
Going back to our ecommerce example for a moment:
# With this line, it's possible that another thread
# updated the status already and this value is stale
status = order.status
# With this line, it's guaranteed that this value is
# consistent with any changes in other threads
status = mutex.synchronize { order.status }
Scenarios around memory visibility are difficult to understand and reason about. That’s one reason other programming languages have defined something called a memory model (Here is Java’s memory model: http://www.cs.umd.edu/~pugh/java/memoryModel/, and here is the one for Golang: http://golang.org/ref/mem), a well-defined specification describing how and when changes to memory are visible in other threads.
Ruby has no such specification yet, so situations like this are tricky to reason about and may even yield different results with different runtimes. That being said, mutexes carry an implicit memory barrier. So, if one thread holds a mutex to write a value, other threads can lock the same mutex to read it and they will see the correct, most recent value.
Mutex performance
As with all things, mutexes provide a tradeoff. It may not be obvious from the previous section, but mutexes inhibit parallelism.
Critical sections of code that are protected by a mutex can only be executed by one thread at any given time. This is precisely why the GIL inhibits parallelism! The GIL is just a mutex, like the one you just saw, that wraps execution of Ruby code.
Mutexes provides safety where it’s needed, but at the cost of performance. Only one thread can occupy a critical section at any given time. When you need that guarantee, the tradeoff makes sense. Nothing is more important than making sure that your data is not corrupted through race conditions, but you want to restrict the critical section to be as small as possible, while still preserving the safety of your data. This allows as much code as possible to execute in parallel.
Given this rule, which of the following two examples is more correct?
require 'thread'
require 'net/http'
mutex = Mutex.new
@results = []
10.times.map do
Thread.new do
mutex.synchronize do
response = Net::HTTP.get_response('dynamic.xkcd.com', '/random/comic/')
random_comic_url = response['Location']
@results << random_comic_url
end
end
end.each(&:join)
puts @results
require 'thread'
require 'net/http'
mutex = Mutex.new
threads = []
results = []
10.times do
threads << Thread.new do
response = Net::HTTP.get_response('dynamic.xkcd.com', '/random/comic/')
random_comic_url = response['Location']
mutex.synchronize do
results << random_comic_url
end
end
end
threads.each(&:join)
puts results
Did you get it? The second one is more correct because it uses a finer-grained mutex. It protects the shared resource (@results), while still allowing the rest of the code to execute in parallel.
The first example defines the whole block as the critical section. In that example, since the HTTP request is inside the critical section, it can no longer be performed in parallel. Once one thread locks that section, other threads have to wait for their turn.
A coarse mutex is unnecessary in this case because the HTTP request doesn’t access anything shared between threads. Similarly, working with the response object doesn’t need to be in a critical section. The response object is created right in the current thread’s context, so we know it’s not shared.
However, the line that modifies @results does need to be in a critical section. That’s a shared variable that could be modified by multiple concurrent threads. If you had used Ruby’s Queue instead of Array, it would have provided the thread-safety guarantees, and you wouldn’t need the mutex here. But two threads modifying the same Array need to be synchronized.
In this case, the performance of the coarse-grained lock example will be similar to single-threaded performance. The performance of the fine-grained lock example is roughly 10x better given that the main bottleneck is the HTTP request.
The takeaway: put as little code in your critical sections as possible, just enough to ensure that your data won’t be modified by concurrent threads.
The dreaded deadlock
Deadlock is probably a term that you’ve encountered before. Whether or not it was in the context of multi-threading, the term probably carried some trepidation. It’s got a deadly kind of sound to it, a bit like ‘checkmate’. Deadlock isn’t unlike checkmate, it essentially means ‘game over’ for the system in question.
A deadlock occurs when one thread is blocked waiting for a resource from another thread (like blocking on a mutex), while this other thread is itself blocked waiting for a resource. So far, this is a normal situation, multiple threads are blocked waiting for mutexes, waiting for the GIL, etc. It becomes a deadlock if a situation arises where neither thread can move forward. In other words, the system comes to a place where no progress can happen.
The classic example of this involves two threads and two mutexes. Each thread acquires one mutex, then attempts to acquire the other. The first acquisition will go fine, then both threads will end up waiting forever for the other to release its mutex.
Let’s walk through an example.
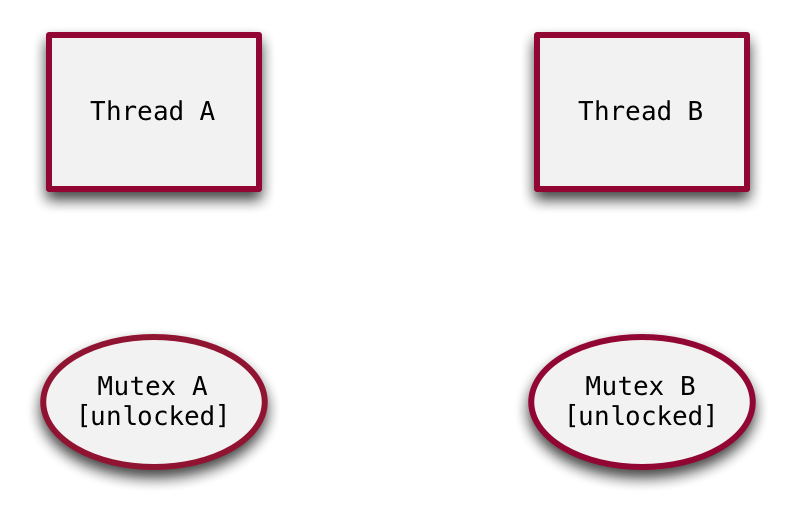
Here’s our starting state, there are two threads and two mutexes.
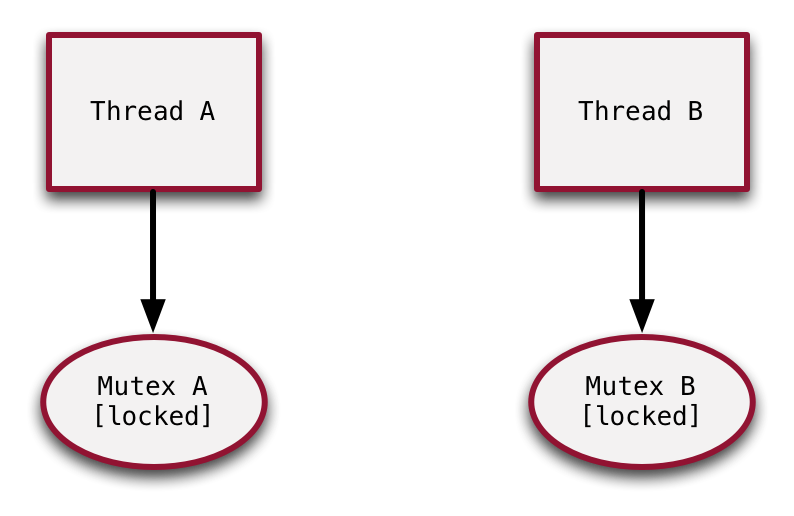
Now each thread acquires one of the mutexes. Thread A acquired Mutex A, Thread B acquired Mutex B. Both mutexes are now in a locked state.

Now the deadlock occurs. Both threads attempt to acquire the other mutex. In both cases, since the mutex they’re attempting to acquire is already locked, they’re blocked until it becomes available. But since both threads are now blocked AND still holding their original mutexes, neither will ever wake up. This is a classic deadlock.
So, what can be done about this? I’ll introduce two possible solutions. The first is based on a method of Mutex you haven’t seen yet: Mutex#try_lock.
The try_lock method attempts to acquire the mutex, just like the lock method. But unlike lock, try_lock will not wait if the mutex isn’t available. If another thread already owns the mutex, try_lock will return false. If it successfully acquires the mutex, try_lock will return true.
This can help in the deadlock situation seen above. One way to avoid deadlock at the last step would have been to use the non-blockingthe non-blocking Mutex#try_lock. That way the threads wouldn’t be put to sleep. But that’s not enough on its own: if both threads had just looped on try_lock, they still would never be able to acquire the other mutex. Rather, when try_lock returns false, both threads should release their mutexes and return to the starting state. From there, they can start again and hope for a better outcome.
With this approach, it’s fine to use a blocking lock to get the first mutex, but try_lock should be used when acquiring the second mutex. If the second mutex is unavailable, that means another thread holds it and is probably trying to acquire the mutex you’re holding! In that case, both mutexes should be unlocked for the dance to begin again. Thanks to the non-deterministic nature of things, one thread should be able acquire both mutexes at some point.
The downside to this approach is that another kind of issue can arise: livelocking. A livelock is similar to a deadlock in that the system is not progressing, but rather than threads stuck sleeping, they would be stuck in some loop with each other with none progressing.
You can see that this is possible using the try_lock solution I outlined here. It’s possible that Thread A acquires Mutex A, Thread B acquires Mutex B, then both try_lock the other mutex, both fail, both unlock their first mutex, then both re-acquire their first mutex, etc., etc. In other words, it’s possible that the threads are stuck in constant action, rather than stuck waiting. So there’s a better solution.
A better solution is to define a mutex hierarchy. In other words, any time that two threads both need to acquire multiple mutexes, make sure they do it in the same order. This will avoid deadlock every time.
Harking back to our example with the diagrams, we already have hierarchical labeling of the mutexes. Mutex A is the obvious choice for a first mutex, and Mutex B the obvious choice for a second. If both threads need both, make sure they start with Mutex A. That way, if one thread acquires Mutex A, it’s guaranteed to have no chance to deadlock on Mutex B. It can do the work it needs to do, then release both mutexes, at which point Thread B can lock Mutex A, and continue down the chain.
Deadlocks can wreak havoc on your system. If a thread is stuck in deadlock, it could be hogging a valuable resource, which blocks still other threads. Be aware of situations where a thread may block on more than one resource, and watch out for deadlocks any time that a thread needs to acquire more than one mutex.